http://lxmls.it.pt/2017/?page_id=65
http://lxmls.it.pt/2017/LxMLS2017.pdf
Day-1: Probabiliy & Python
The first day of the school is more like warming up session, which includes (1) an overview of probability (by Mario A. T. Figueiredo), and (2) an introduction to Python (by Luis Pedro Coelho) for making everyone in the same starting point. The Python tutorial is very compact but informative, which can be found in the speaker's github repo.
https://github.com/luispedro/talk-python-intro
Day-2: Linear Learners
The morning session introduces linear learners by STEFAN RIEZLER, including:
- Naive Bayes
Perceptron - Logistic Regression
- Support Vector Machines
Furthermore, the speaker talked about convex optimization for learning parameters of these models, especially, how to use Gradient Descent / Stochastic Gradient Descent to reach the minimum.
 |
| Figure 1 |
The bottom line about the difference between Batch (Offline) & Stochastic (Online) learnings is online learning do each update based on each random (stochastic) sample in the training dataset while the former one do each update based on all of the samples in the training dataset in the current big data era in terms of the majority of problems.

Evening talk was given by FERNANDO PEREIRA from Google, who is Distinguished Scientist at Google, where he leads projects in natural-language understanding and machine learning. The talk "LEARNING AND REPRESENTATION IN LANGUAGE UNDERSTANDING" gives some work at Google using deep learning as well as Knowledge Graphs for learning & representing language for various applications in their products.
Noah Smith from Uni. of
Obviously, as the strong assumption (independence of each word) is not usually the case on NLP, the simple model performs poorly on modeling language.
To make the model better, a simple improvement is based on the idea that each word depends on its previous word, which becomes 1st Order Markov Model. In the same way, we can extend the model by the word depends on its m previous words, which becomes m-th


XAVIER CARRERAS from XEROX, which is now Naver (Google in South Korea) Labs Europe, gave the lecture on learning structured predictors using Named Entity Recognition (NER) as an example.
A simple model is decomposing the prediction of the sequence of labels into predicting each label at each position, which named localclassifers ( i i

The direct comparison between between localclassifiers

Day-3: Sequence Model
- Markov Models
- Hidden Markov Models (HMMs)
- Viterbi Algorithm
- Learning Algorithms for HMMs
A basic model with strong independence of each word is Bag stopwords
 |
| Figure 2 |
To make the model better, a simple improvement is based on the idea that each word depends on its previous word, which becomes 1st Order Markov Model. In the same way, we can extend the model by the word depends on its m previous words, which becomes m-
 |
Hidden Markov Model (HMM) is a model over sequence

In other words, HMM is a joint model over observable symbols and their hidden/latent/unknown classes.
For instance, in PoS PoS classies

Then we can move on to the decoding problem: given the learned parameters & a new observation sequence, find the "best" sequence of hidden states. And with a different definition of "best", we have different approaches such as (1) posterior decoding, and (2) viterbi
For example, the "best" is different in each of the following two problems:
- Pay 1EUR if we get the sequence wrong
- Pay 0.1EUR for every wrong label/class for each word
Viterbi decoding is for the first problem, which aims at finding the most probable sequence of hidden states, and posterior decoding is for the second problem. Viterbi algorithm can be explained by the matrix below where rows denote all the states, and columns denote a sequence. Then, the algorithm proceeds from left to right:
compute to find backtrack
 |
| Viterbi Algorithm |
Evening talk was given by ALEXANDRA BIRCH from Uni. of works done by their group on MT, and comparative performance on the WMT against other submissions. Importantly, the speaker talked models that smaller, faster and deeper, which can be trained in a usual environment in an academic setting (with limited resources). slides
Day-4: Learning Structured Predictors
XAVIER CARRERAS from XEROX, which is now Naver (Google in South Korea) Labs Europe, gave the lecture on learning structured predictors using Named Entity Recognition (NER) as an example.
A simple model is decomposing the prediction of the sequence of labels into predicting each label at each position, which named local

The direct comparison between between local

Q: How can we incorporate the feature-rich & label interactions together?
Log-linear models

Day-6 is about neural networks from BHIKSHA RAJ (CMU).
Then BHIKSHA RAJ explained why deep matters...
Q: When we should call a deep network? Usually we call is a deep network when we have more than 2 hidden layers.
Deeper networks may require exponentially fewer neurons than shallower networks to express the same function.
The second topic of this lecture is about learning NN parameters, which includes how to define input/output, error/cost functions, backpropagation , and convergence of learning. The final slide of the lecture showed how different approaches for optimizing gradient descent converge with time by Sebastian.
In the evening, GRAHAM NEUBIG from CMU gave an introduction to "SIMPLE AND EFFICIENT LEARNING WITH DYNAMIC NEURAL NETWORKS" using DyNet, which is a framework for the other paradigm - Dynamic Graphs compared to Static Graphs used in TensorFlow and Theano.
The final lecture of the summer school was given by CHRIS DYER from CMU & DeepMind.

The problem of RNN is vanishing gradients, i.e., we cannot adjust the weight of h1 based on the error occurred at the end.
 Then, the speaker talked about conditional language models, which assigns probabilities to sequences of words given some context x (e.g., the author, an image etc.). One of the important part is then how to encode the context into a fixed-size vector, which has been proposed with different approaches such as conventional sequence models, LSTM encoder etc.
Then, the speaker talked about conditional language models, which assigns probabilities to sequences of words given some context x (e.g., the author, an image etc.). One of the important part is then how to encode the context into a fixed-size vector, which has been proposed with different approaches such as conventional sequence models, LSTM encoder etc.
Evening talk: KYUNGHYUN CHO from New York Uni. & Facebook AI research gave a practical talk on "NEURAL MACHINE TRANSLATION AND BEYOND", which includes the latest (a few weeks...) progress of neural machine translation. The talk first showed the very neat history of machine translation, and then showed how neural machine translation models have taken over and became the state-of-the-art on different language translation.
Log-linear models

Day-5: Syntax and Parsing
Yoav Goldberg from Bar Ilan University gave the lecture on syntax and parsing.

Parsing with a PCFG is finding the most probable derivation for a given sentence. CKY algorithm is an algorithm for doing that.
 Dependency trees capture the dependency between words in a sentence. Three main approaches of dependency parsing were introduced. The first approach is parsing the sentence to constituency structure, and then extract dependencies from the trees. The second graph-based approach (Golbal Optimization), which define a scoring function over (sentence, tree) pairs, and then search for the best-scoring structure. Finally, the
Dependency trees capture the dependency between words in a sentence. Three main approaches of dependency parsing were introduced. The first approach is parsing the sentence to constituency structure, and then extract dependencies from the trees. The second graph-based approach (Golbal Optimization), which define a scoring function over (sentence, tree) pairs, and then search for the best-scoring structure. Finally, the transition-based approach starts with an unparsed sentence, and apply locally-optimal actions until the sentence is parsed.
In the evening, there was a demo session by dozens of companies working on ML/DL with respect to various areas. It is interesting to see how ML/DL is transforming the world in so many domains such as medicine search, energy, government etc.
The last two days of the summer school talked about deep learning, which is so hot recent years, especially with the successful applications in the areas such as speech recognition, computer vision, and NLP, thanks to the big data & advanced computing powers.
 |
| Parsing |
- What is parsing?
- Phrase-based (constituency) trees (PCFG, CKY)
- Dependency trees (Graph parsers, transition parsers)
Parsing is dealing with the problem of recovering the structure in natural language (e.g., linguists create Linguistic Theories for defining this structure). Understanding the structure is helpful for other NLP tasks such as sentiment analysis, machine translation etc. And different the structure in yesterday, the structure in day-5 is hierarchical one.

CFG (Context Free Grammer) is an important concept for parsing, which presented on the left.
PCFG (Probablistic CFG) is like a CFG, but each rule has an associated probability, and our goal is then get a tree with maximum probability.
Parsing with a PCFG is finding the most probable derivation for a given sentence. CKY algorithm is an algorithm for doing that.
 Dependency trees capture the dependency between words in a sentence. Three main approaches of dependency parsing were introduced. The first approach is parsing the sentence to constituency structure, and then extract dependencies from the trees. The second graph-based approach (Golbal Optimization), which define a scoring function over (sentence, tree) pairs, and then search for the best-scoring structure. Finally, the
Dependency trees capture the dependency between words in a sentence. Three main approaches of dependency parsing were introduced. The first approach is parsing the sentence to constituency structure, and then extract dependencies from the trees. The second graph-based approach (Golbal Optimization), which define a scoring function over (sentence, tree) pairs, and then search for the best-scoring structure. Finally, the In the evening, there was a demo session by dozens of companies working on ML/DL with respect to various areas. It is interesting to see how ML/DL is transforming the world in so many domains such as medicine search, energy, government etc.
The last two days of the summer school talked about deep learning, which is so hot recent years, especially with the successful applications in the areas such as speech recognition, computer vision, and NLP, thanks to the big data & advanced computing powers.
 |
Day-6: Introduction to Neural Networks
Day-6 is about neural networks from BHIKSHA RAJ (CMU).
- Neural Networks (NN) and what can they model
- Issues about learning
NN have established state-of-the-art in many problems such as speech recognition, Go. NN began as computational models of the brain. The NN models have been evolved from the earliest model of cognition (associationism ), the more recent model (connectionist ), and current NN models (connectionist machines).
BHIKSHA RAJ also showed how NN can model different functions from boolean to the function with complex decision boundaries using Multi-Layer Perceptrons (MLP). An interesting fact is that the analysis of weights in the perceptron . He explained that neuron fires if the correlation between the weight pattern and the inputs exceeds a threshold, i.e., perceptron is acturally a correlation filter!
Then BHIKSHA RAJ explained why deep matters...
Q: When we should call a deep network? Usually we call is a deep network when we have more than 2 hidden layers.
Deeper networks may require exponentially fewer neurons than shallower networks to express the same function.
 |
| http://ruder.io/optimizing-gradient-descent/index.html |
In the evening, GRAHAM NEUBIG from CMU gave an introduction to "SIMPLE AND EFFICIENT LEARNING WITH DYNAMIC NEURAL NETWORKS" using DyNet, which is a framework for the other paradigm - Dynamic Graphs compared to Static Graphs used in TensorFlow and Theano.
 |
| Static Graphs (TensorFlow, Theano) |
 |
| Dynamic Graphs (Chainer, DyNet, PyTorch) |
Day-7: Modeling Sequential Data with Recurrent Networks
The final lecture of the summer school was given by CHRIS DYER from CMU & DeepMind.
- Recurrent Neural Networks (RNN, in the context of language models)
- Learning parameters, LSTM
- Conditional Sequence Models
- Machine Translation with Attention
The main difference between Feed-forward NN and RNN is the later one incorporates the history at current process.

The problem of RNN is vanishing gradients, i.e., we cannot adjust the weight of h1 based on the error occurred at the end.
 |
| Visualization of LSTM: Christopher Olah |
 Then, the speaker talked about conditional language models, which assigns probabilities to sequences of words given some context x (e.g., the author, an image etc.). One of the important part is then how to encode the context into a fixed-size vector, which has been proposed with different approaches such as conventional sequence models, LSTM encoder etc.
Then, the speaker talked about conditional language models, which assigns probabilities to sequences of words given some context x (e.g., the author, an image etc.). One of the important part is then how to encode the context into a fixed-size vector, which has been proposed with different approaches such as conventional sequence models, LSTM encoder etc.
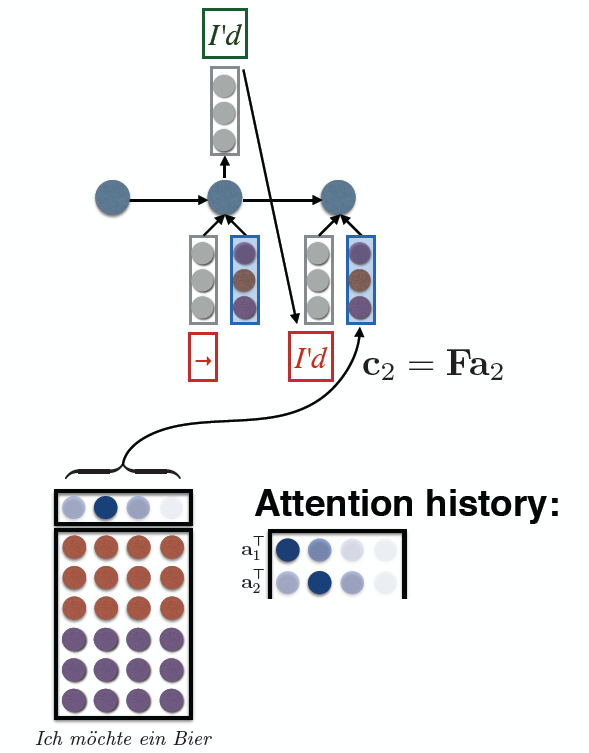
Next part of the lecture is about Machine Translation with Attention. In translation, each sequence is represented as a matrix where each column is a vector for the corresponding word in the sequence. Attention gives
In the end, some tricks, e.g., depth of the models, and mini-batching have been introduced. An interesting observation is that depth seems less important with respect to text compared to audio/visual processing. One possible hypothesis might be more transformation of the input is required for ASR, image recognition, etc.,
Evening talk: KYUNGHYUN CHO from New York Uni. & Facebook AI research gave a practical talk on "NEURAL MACHINE TRANSLATION AND BEYOND", which includes the latest (a few weeks...) progress of neural machine translation. The talk first showed the very neat history of machine translation, and then showed how neural machine translation models have taken over and became the state-of-the-art on different language translation.
About the summer school:
It was a really great summer school with lectures provided by experts (of course with a big effort by the organizers), and I'd like to highly recommend it for anyone who is interested machine learning and deep learning. And if you're familiar with the topics covered by the summer school, I expect you will get many fresh and views on what you already-known. If you are not familiar with those topics like me, you can also get a pretty good overview and starting points for adopting these techniques for your problem.
No comments:
Post a Comment