Recommendation Systems require three components to provide recommendations:
- Background data (info.
that - Input data (provided by user)
- Recommendation algorithm
Non-Personalized Recommendation: Based on populations' average opinions
-> Lack of context, come with problems while your taste diverse from the average

Source: https://www.youtube.com/watch?v=JEYLfIVvR9I
* Collaborative Filtering (CF):
Assumption: If a person A has the same opinion as a person
1. Aggregate ratings for items from different users (Rating records of users)
2. User profile
3. Use the background data to calculate
- Challenges
1). New items or new users
2). Sparsity of data will affect recommendations (Balabanovic and Shoham 1997), (The number of ratings is low compared to the number of items)
- Two approaches for CF
1). Model-based approach (SVD, or Matrix Factorization)
2). Memory-based approach (Similarity between item-item or user-user)
* Content-based recommendation:
The content-based approach (Mooney and Roy 2002) recommends a user to items whose content is similar to content that the user has previously viewed or selected.
1. Use the features of the items
2. User preference in terms of content features
*Knowledge-based recommendation:
-------------------------------------------------------------------------------------------------------------------------
Prediction Accuracy:
* Measuring Ratings Prediction Accuracy
1. Root Mean Squared Error (RMSE): Square of (Predicted - Actual Rating)
RMSE=1n∑i=1n
2. Mean Absolute Error (MAE): Absolute of (Predicted - Actual Rating)
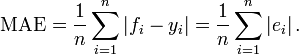
* Measuring Usage Prediction (does not predict
1. Precision (P@N)
2. Recall
3. F-Measure
4. MAP (Mean Average Precision)
5. MRR (Mean Reciprocal Rank)
When the # of recommendations is preordained (determined), use the precision-recall curves
Precision-recall curves emphasize the proportion of recommended items that are preferred while ROC curves emphasize the proportion of items that are not preferred that end up being recommended.
-------------------------------------------------------------------------------------------------------------------------
Some other metrics rather than accuracy: Sometimes you don't need the similar things to what you have bought, but rather would like to some fresh ones or even surprise!
Diversity: Things that are not in the same categories etc.
Serendipity: Things that you didn't expect etc. Business Goal: get people to consume less popular items.
-------------------------------------------------------------------------------------------------------------------------
- Useful Tools
LensKit ) - Apache Mahout (Java, Use Hadoop for scalability, General ML capabilities, several recommender algorithms)
MyMediaLight ( GraphLab RankLib
- Useful books and Course
- Recommender systems handbook
- Introduction to recommender systems (Coursera)
-------------------------------------------------------------------------------------------------------------------------
No comments:
Post a Comment